本文为J. Alworth[^1]等人与2021年发表在Acta Astronautica期刊上的一篇论文。主要介绍了一种基于迁移学习的空间(碎片)目标的光变曲线分类算法。
摘要
本文所做的主要工作有:
- 提出了一个适用于空间目标的1D卷积分类器,能够使用仿真/真实光变数据对SO的形状进行分类
- 成功应用了迁移学习,提升了本文网络在真实光变上的分类精度。作者使用3D光线追踪软件来生成高真实度(high fidelity)的仿真数据,在仿真数据上对模型进行预训练,然后使用真实数据来对网络进行微调。
- 本文迁移学习的方式,对比纯使用真实数据训练的方式,有着更好的变现,该现象能够说明(indicate)迁移学习能够在真实光变数据缺失的情况下,更有效地使用深度学习技术。
本文使用自行构造仿真数据集、MMT数据集上进行预训练,然后将模型迁移至EOS数据集并进行了测试,得到了不错的效果。(TODO: 补充实验结果)
引言
本文在引言部分提到的背景为空间态势感知(Space Situational Awareness, SSA)。在该领域中,空间目标特别是空间碎片的特性是十分重要的信息。然而,绝大多数的空间碎片的关键特性是缺失的,这些特性包括目标的大小、形状、材质、旋转姿态等。这些信息对于目标轨道的精确预测是十分重要的。常驻空间目标(Resident Space Object, RSO)的特性通常使用地基观测手段来获取。
本文将目光聚焦于RSO的光变曲线。光度数据是地基观测中最容易获取的数据,亮度随着时间变换的曲线被称为光变曲线。光变曲线中,将RSO的大小、形状、材质等特性耦合进了目标的亮度变化中,对光变曲线的分析与反演能够对目标的特性做出一些估计。
然而,目前针对RSO的光变曲线反演方法,仅能在仿真数据集上,实现对简单形状与姿态的估计,这些方法尚未在真实光变数据上取得成功(论文作者观点)。
目标的特性与其亮度之间,是一个复杂的非线性关系。考虑到深度学习能够从数据中学习出这种复杂非线性关系,深度学习逐渐进入了光变反演研究者的视野。目前,在RSO光变反演中应用深度学习所面临的困难,主要集中在数据集方面。理论上来说,深度神经网络的规模越大,越能拟合出更加真实的关系,但响应的需要的训练数据量也越大。目前RSO光变曲线领域却十分缺少带有标注的数据(Labelled Dataset)。
为了绕开数据集,使得神经网络能够在数量不足的真实数据上达到较好的效果,本文采用了迁移学习的方法,使用仿真工具制造出大量的仿真光变数据集,在仿真数据集上进行预训练,接着使用真实数据集对网络进行微调(Fine-Tune),从而在insufficient的真实数据集上,得到一个效果还不错的网络模型。
本文的主要工作如下:
- 设计并使用高保真度(high fidelity)的方法来仿真光变数据作为训练集(其实就是用blender的光线追踪引擎去仿真光变),用来提升神经网络的基准表现(boost the performance of neural network models for RSO characterisation based on the principles of transfer learning);
- 设计了一个以CNN为骨干的网络,通过迁移学习,在仿真和真实数据集上得到很好的表现;
- 证明了迁移学习能够提升网络在真实光变数据上的表现,这种方法降低对well labelled数据的需求。
Methodology
1. 光变仿真环境
本文的光变仿真工具力求生产出高保真度的仿真光变曲线(high fidelity)。仿真将使用给定的RSO几何与材质模型、轨道参数以及地基观测位置作为输入。根据这些信息来生成一系列的光变测量值,测量值的物理量为视星等。整个仿真过程如下图所示: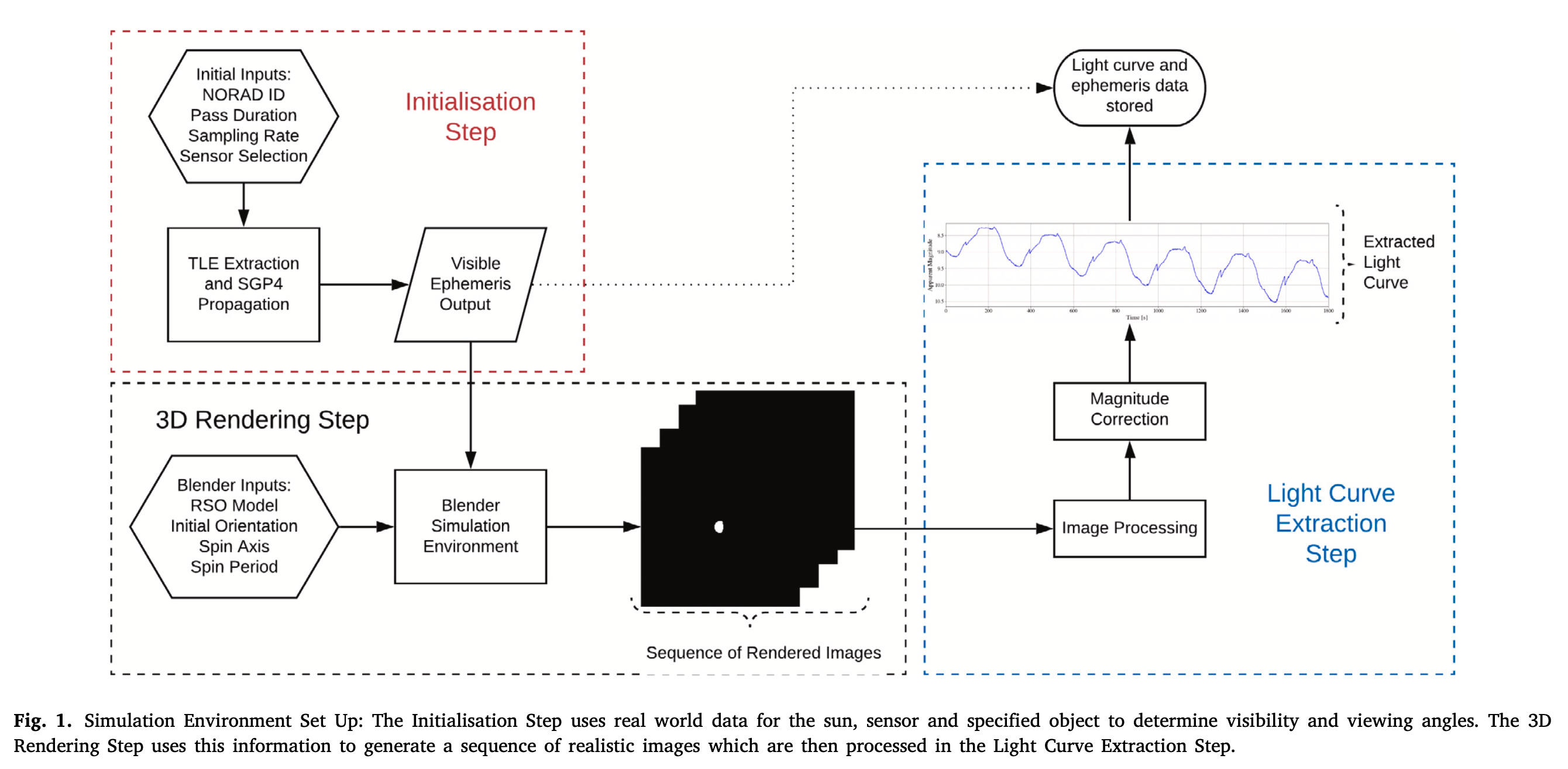
整个仿真过程分为三大部分:
- 初始化部分。初始化步骤中,设定目标ID、观测时长、采样频率、传感器参数配置,同时将卫星轨道信息输出为星历数据,获取观测几何。
- 3D渲染部分。该步骤输入目标的形状模型、初始姿态、自转轴与自转周期,然后根据星历数据,自动仿真出图像序列
- 光变提取部分。对渲染图像进行处理,将图像数据提取成目标的视星等,结合观测时间,构建光变数据。
Step: Initialization
所谓初始化步骤,其主要工作是根据目标的轨道信息、观测者位置信息、时间信息生成标准的星历文件,方便后续仿真时使用。
Step: 3D Rendering
3D渲染步骤中,使用RSO的几何模型与材质信息,设定初始姿态和自转轴、自转周期,根据上一步的星历信息,得到观测时刻的目标位置与姿态、太阳方位、观测位置,使用Blender的Cycle光线追踪引擎进行渲染,从而得到一系列的仿真图像。
Step: Light Curve Extraction
这一步骤的目的是为了从仿真得到的图像中计算出目标的视星等。计算视星等的基本原理公式为:
$$
m_1 = m_2 + I_{m_1} - I_{m_2}
$$
其中,$m_2$为一个基准目标的视星等(例如恒星),该目标有一个已知的视星等,$I_{m_1}$与$I_{m_2}$则为从图像中提取出来的观测目标与基准目标的仪器星等。在理想传感器上,仪器星等与视星等之间是线性关系,因此通过二者的仪器星等的差异,能够直接从基准目标的视星等推算出目标星等。
类似的道理,在仿真过程中,上述公式中的基准目标,选择为一个Flat Facet Model。在仿真的时候,使用同样大小、材质的FFM,在同样的观测几何条件下进行仿真。最终的计算公式为:
$$
m_1 = m_{ff} = I_{m_b} - 2.5\log_{10}{\frac{B}{t_{exp} \cdot (\frac{d}{d_r} \cdot scale)^2}}
$$
其中,$m_{ff}$为flat plate在10000m出的绝对星等(这一部分如何计算的?),$I_{mb}$其相应的仪器星等,B是目标的所有像素的亮度和,$t_{exp}$是曝光时间,$d$是在Blender渲染中目标与观测者之间的距离,$d_r$是基准目标与观测者之间的距离,即10000m,scale是Blender渲染时,设置距离与实际距离之间的比例系数(因为如果按照实际距离,Blender仿真无法成像)。这个计算过程的问题就在于,如何得到$m_{ff}$与$I_{m_b}$。
Post Processing
在得到仿真光变后,为了尽可能模拟真实数据的情况,需要进行后处理。仿真数据有着统一的采样长度和1s的均匀采样间隔,然而实际数据中,通常不会有统一的采样长度和均匀的采样间隔,会由于各种原因造成信号中断。本文采用如下的后处理,来模拟真实观测中的这种情况:
- 使用高斯分布的随机数,随机选取数据段的起始与终止
- 采样频率上,模拟了EOS数据集,60%的数据设置为1Hz,30设置为0.5Hz,10设置为0.33Hz
- 同样使用高斯分布来随机去掉某些时刻的观测值,以模拟云层遮挡的情况
真实光变数据提取
本文所使用的真实数据集包括EOS,该数据集是由位于澳大利亚两个观测站的六台望远镜所获取的数据,原始数据为巡天的图像数据,需要从图像中获取光变。
从图像中获取光变的如下图所示:
- 使用平场、暗场图去掉noise;
- 从图像中区分天空背景与目标,同时使用快速傅里叶变换FFT来增强暗目标的识别;
- 使用PhotUtils从图像中寻找出恒星与目标,并计算出它们的视星等;
- 从图像中找出所要寻找的目标,剔除恒星,得到目标的视星等;
- 遍历所有时刻的图像,得到目标的光变曲线。
视星等是通过仪器星等计算出来的,对于EOS数据集,六台望远镜仪器星等与视星等之间的转换关系是确定的,只要计算出仪器星等,即可得到对应的视星等。目标仪器星等计算公式为:
$$
I_m = -2.5\log_{10}{\frac{N_{ap} - A_{ap}S_{sky}}{t_{exp}}}
$$
其中,$I_m$是目标的仪器星等,$N_{ap}$是目标所开的aperture中所有像素的灰度和,$A_{ap}$是aperture的面积,$S_{sky}$是星空背景的值(每像素的信号),$t-_{exp}$为曝光时间。
通过上述的过程,将EOS的图像数据转换为了对应目标的光变数据。
分类模型
本文以1D CNN为主干,构建了一个适用于利用光变数据进行目标分类的网络: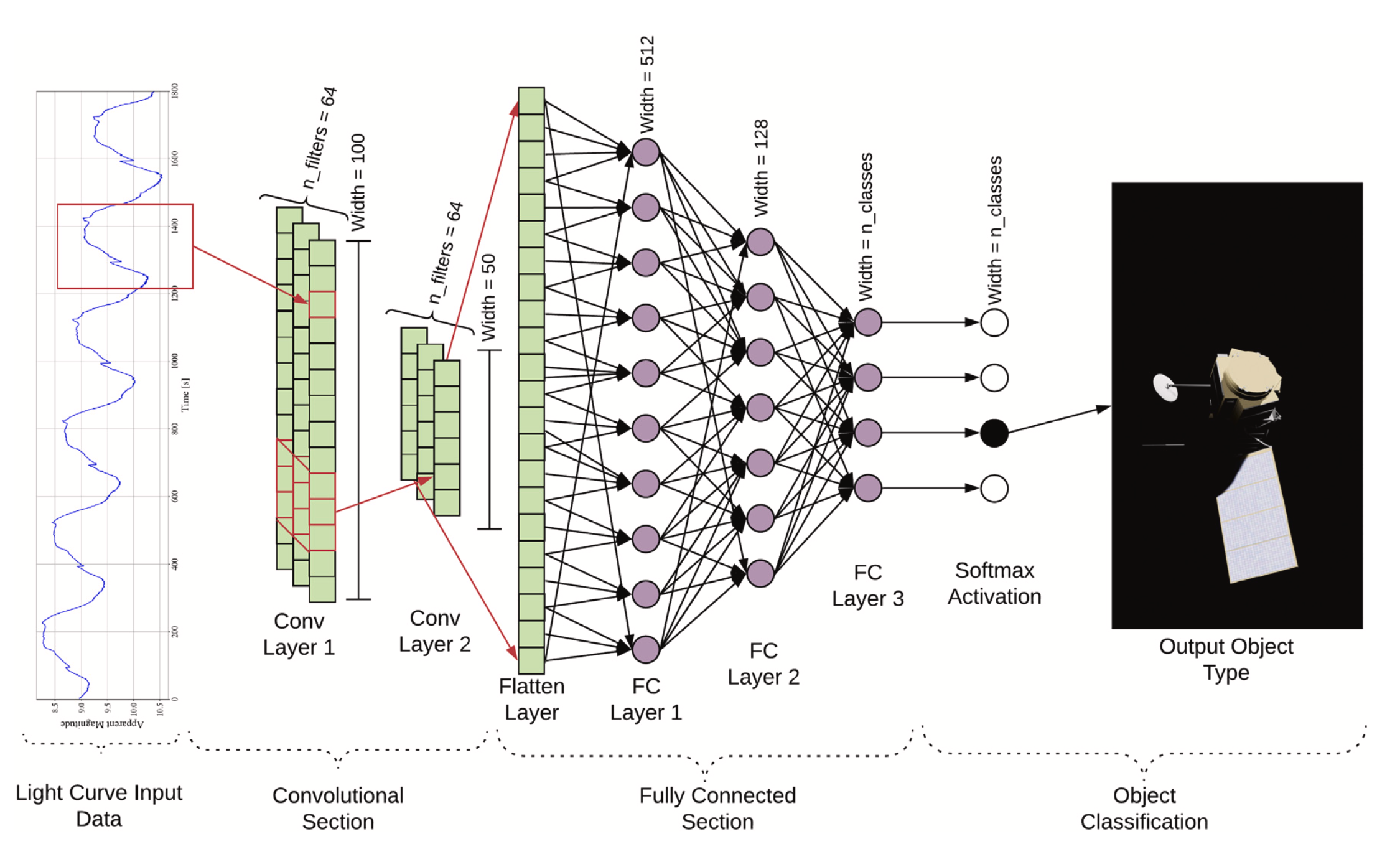
整个网络分为两个Section,第一个Section包含两个卷积层,第二个Section包含3个全连接层,最后使用Softmax激活来实现目标分类。
1D CNN层包含了两个卷积层,每个卷积层之后都紧接着一个max pooling和一个bactch-norm。每个卷积层的stride都设置为3,不进行padding。
将卷积层的输出进行flat,作为输入传递给全连接层。本文网路共有3个全连接层,每个全连接层之后都有一个dropout和batch-norm。除最后一个全连接层外,卷积与全连接层的激活函数均为ReLU。最后一个全连接层使用softmax作为激活函数,实现最终的分类。
对于RSO类的物体,其亮度主要来源于反射太阳光,因此观测几何关系也会对目标的亮度产生影响。很多RSO自身都存在旋转,这是一段观测内引起亮度变化的主要因素。为了使网络能够将上述的因素加入拟合过程,除了星等外,以下三个数据也一并作为输入:
- 太阳-目标-观测者相角
- range(这里指的是目标的大小还是观测距离?不确定)
- 相对初始观测的时间(单位秒)
本文最终所使用的真实数据集是EOS,该数据集每一段观测持续20分钟,因此输入光变数据的长度设置为1200,并基于该长度对数据进行截取与补零。
迁移学习
本文的迁移学习过程如下图所示: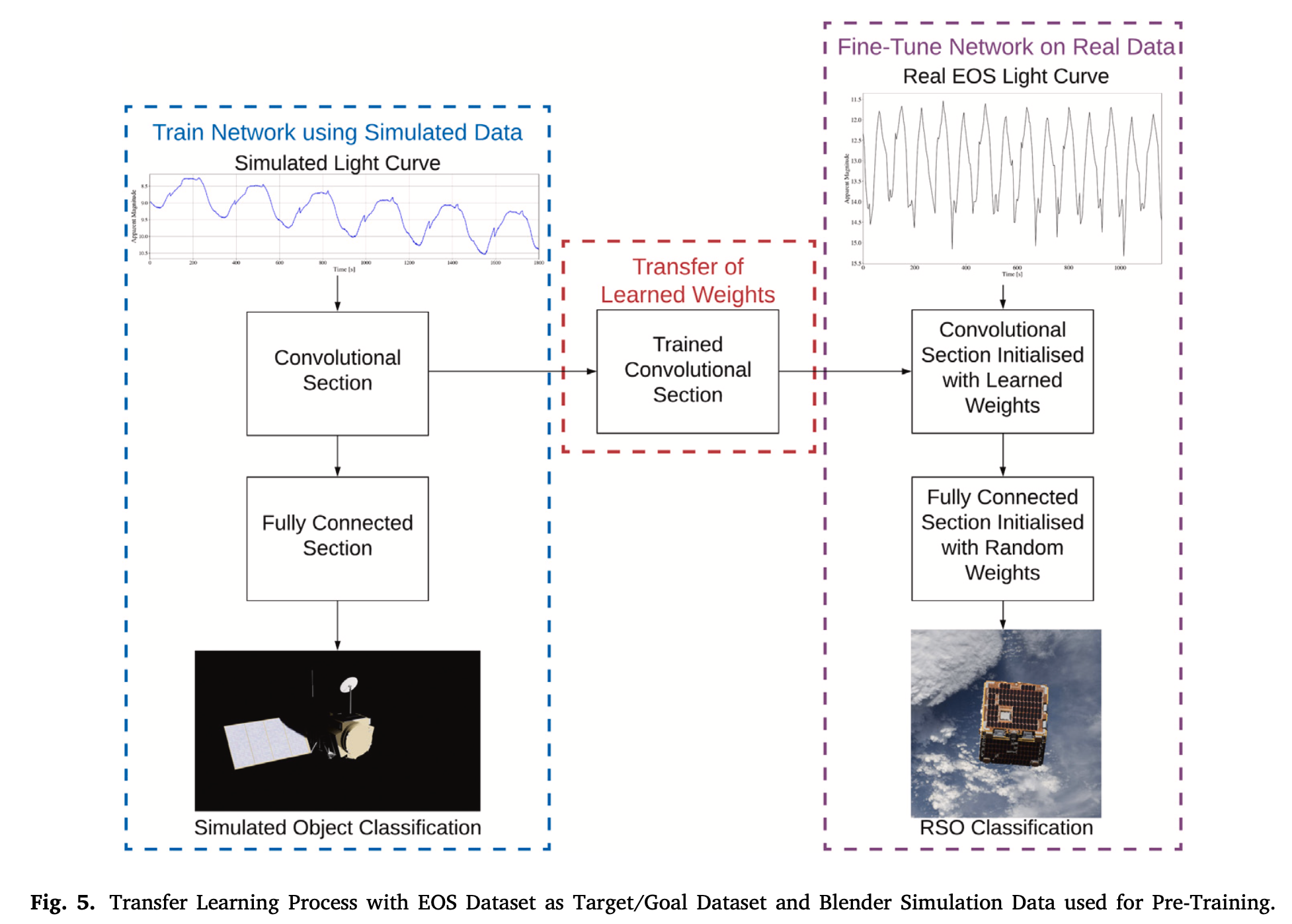
将预训练的模型进行迁移学习,其意义在于无需从头开始训练。在使用仿真数据进行预训练时,卷积Section、全连接Section部分的参数从随机设置开始,全部进行训练。当模型迁移到EOS数据上时,使用预训练的卷积Section作为Fine-Tuning的起始参数进行训练,而全连接Section的权重则重新初始化进行训练。由于数据量少,且卷积Section的参数从预训练好的模型中初始化,因此只需要较少的时间即可完成在EOS上的训练。
实验设置
本文的第三部分对数据集、模型设置及超参数配置进行介绍。
Blender仿真数据集
在本文中,使用Blender生成了4500条光变数据,这些数据来自于13类不同的卫星模型。每条光变的采样间隔为1s,每次仿真观测持续30min,即一条观测有1800个采样点。在仿真的初始化步骤中,生成不同观测相角、不同距离条件的TLE轨道文件,用来在仿真中确定太阳-目标-观测者之间的相对位置关系。观测目标的初始姿态、自转周期与自转轴将随机生成,自转周期在10s到300s之间随机生成,自转轴从三个主轴之间随机生成。自转特性的配置,将尽可能覆盖不同类型目标的自转状态。本文所创建的仿真数据中,尚未包含翻腾或自转很慢的目标,这部分内容作者声称将在后续工作中进行。
EOS数据集
截止作者成文时,EOS包含了9类configuration目标和22个unique目标的900多条光变数据。由于EOS原本的目标是跟踪火箭残骸这种large rotation objects,导致该数据集里约60%的目标都集中分布在3类不同的火箭结构体的类别中。这使得EOS成为了一个极度不平衡的数据集,甚至有3个分类,只包含了1个目标。
MMT数据集
Multichannel Monitoring Telescope(MMT)提供了另一个公开的RSO光变数据集。该数据集也将作为本文网络的训练与测试数据集。MMT数据集中的数据非常多,已经包含了10000个目标左右的数据量。本文中,只有拥有确定的自转周期,且超过500个独立观测的目标,才被选作数据集中的一员。
基于上述标准,有154个目标的40000条光变曲线被选入数据集中,这些目标被分到27个类别中。与EOS数据相同,这些数据也是极度unbalance的数据,最大的三个类别包含了75%的数据。为了本文的实验,在上述筛选的基础上,从8个数量较多的类别中,每一类选取500条光变,创造一个balanced数据,用于实验对比分析。
网络模型设置与超参数配置
训练过程中的超参数配置在table 1中给出。由于仿真数据集与MMT数据集的数量较多,因此batch size给的大一些。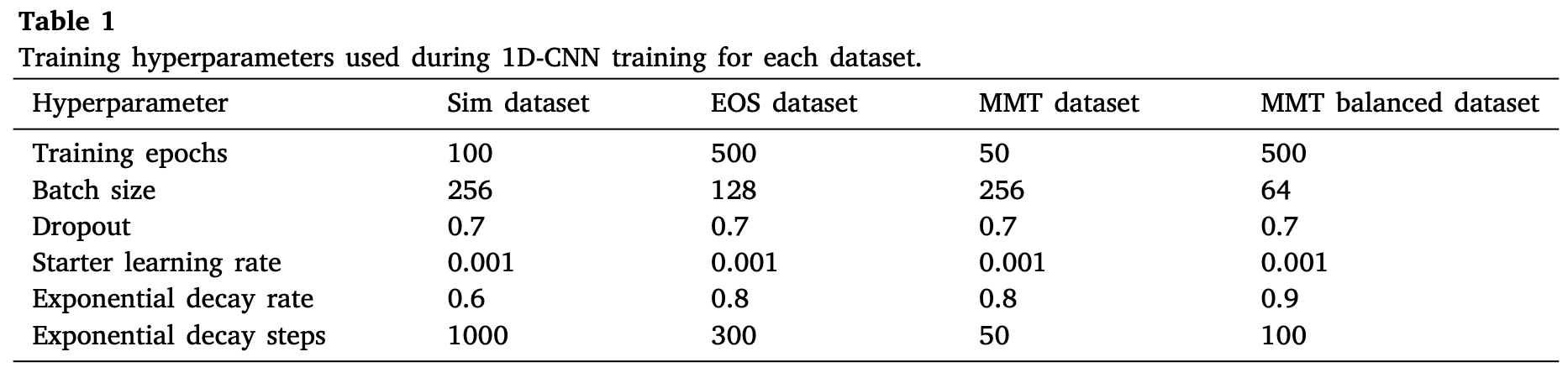
在训练过程中,选择5取4的方式来进行训练,即5组训练数据中,选择4组进行training,1组进行validation,直到每一组数据都被作为一次validation。
对于EOS与MMT的imbalanced数据,类别权重被考虑仅loss function中,从来提升网络的性能。
迁移学习过程中,哪些层进行迁移,哪些层的参数会被fine-tuning,这些也是超参数的一部分,在table 2中进行了展示: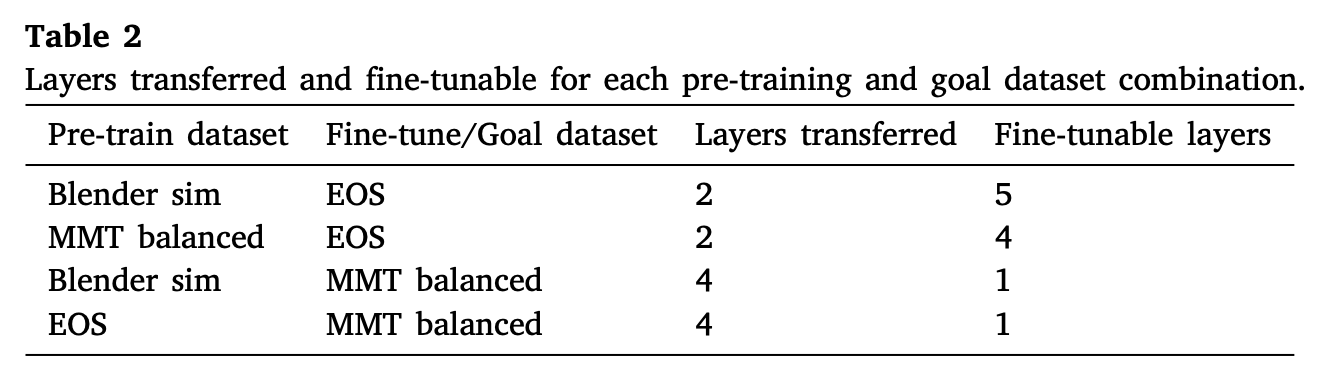
从表中可以看出,本文分别使用不同的数据集组合来进行预训练与fine-tuning,不同的迁移学习策略有着不同的迁移层。
实验结果
1D CNN网络性能分析
本文作者首先不进行迁移学习,直接在不同数据集上使用不同方法进行分类,结果如下表所示: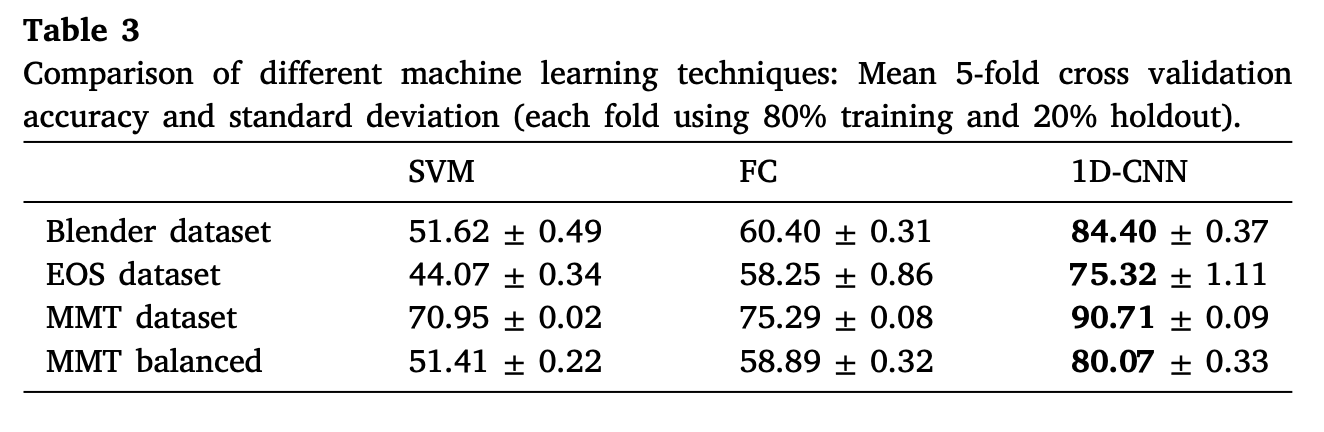
从表中可以看出,支持向量机(SVM)在所有数据集上都有着最差的分类精度表现,FC方法(4层稠密全连接层)结果稍好一些,本文的1D-CNN网络有着最好的分类精度表现。1D CNN方法在仿真数据与EOS数据上的Confusion Matrix如下所示: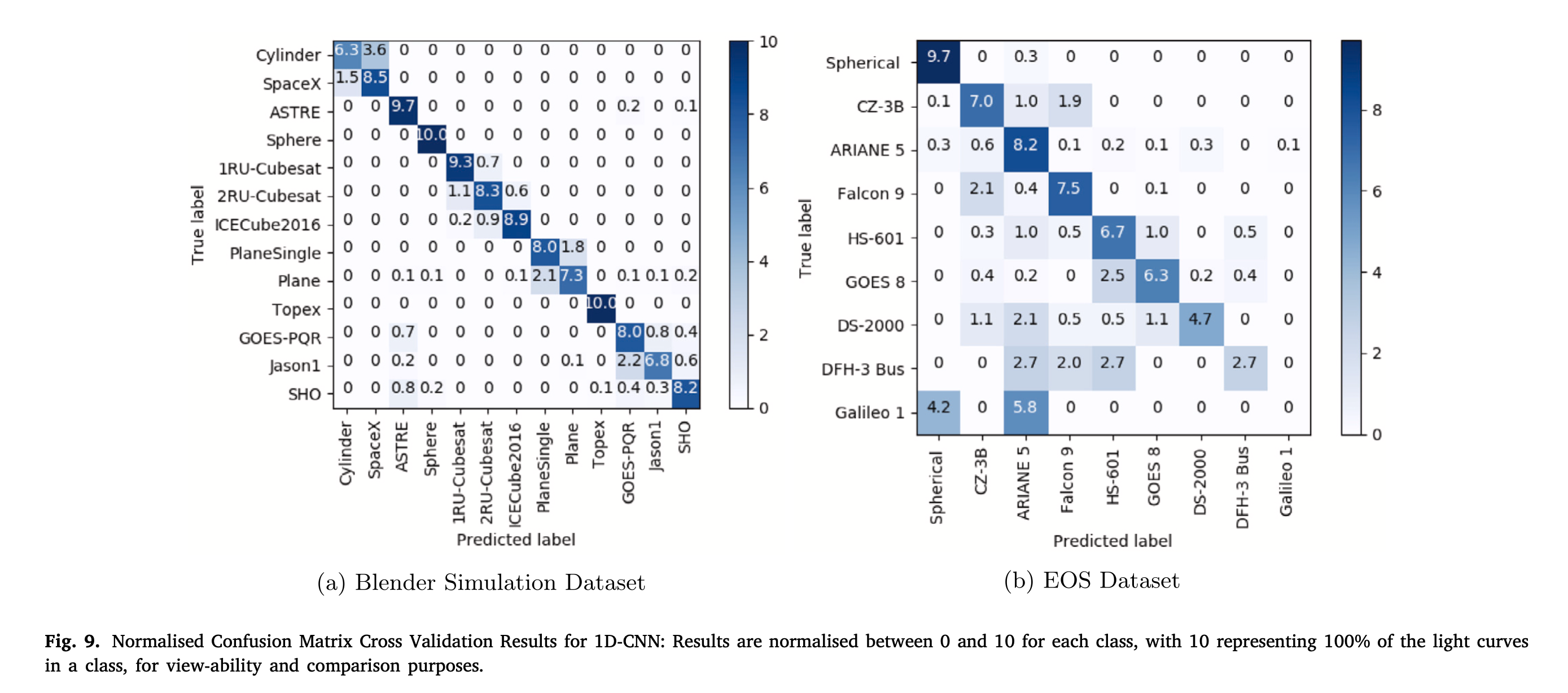
在仿真数据上,13个类别的综合精度为84.4%,出现误分类的类别主要集中于形态较为近似的类别,如Cylinder类别与SpaceX。在EOS数据集上,9类目标的综合精度为75.3%,网络对于Spherical类别的分类效果最好,这是由于该类目标的光变曲线形态有着较强的独特性。与仿真数据的情况相同,误分类的问题主要集中在3类形状相似的火箭结构体类上(CZ-3B型、ARIANE 5型、FALCON 9型)。下表展示了在EOS数据集上的F1 Score,以及不同类别的数据所占的比例: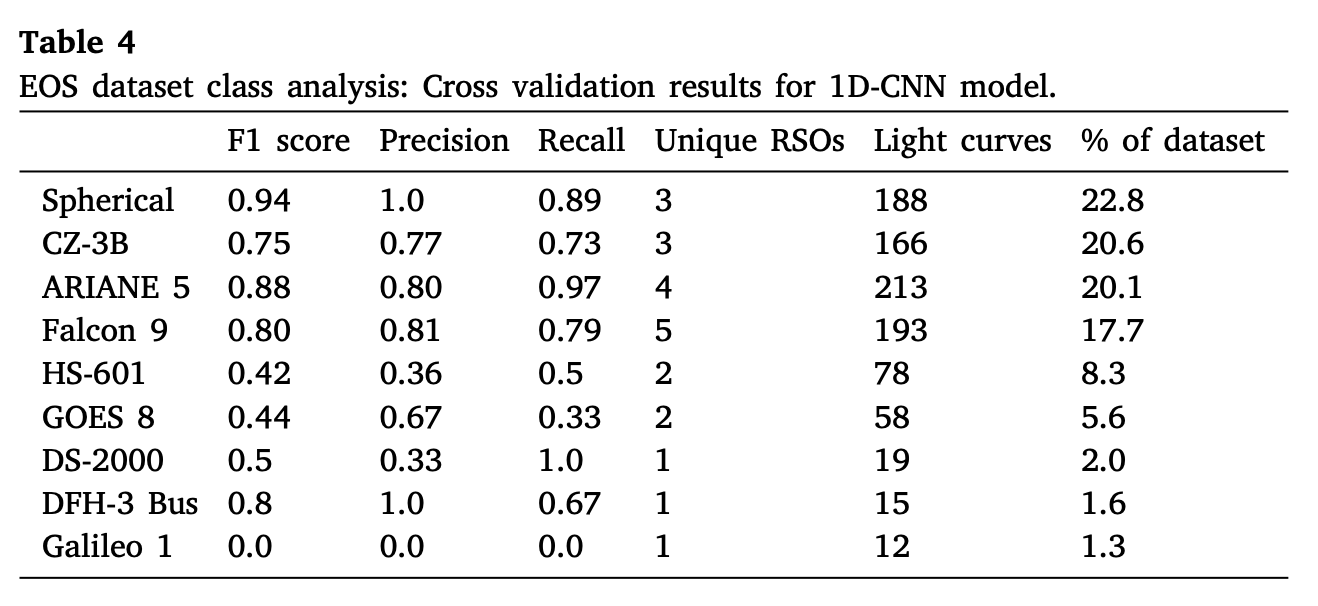
从表格中可以看出,尽管对不平衡数据进行了加权,但分类效果仍然随着所占比例的减小而降低。
在未经过平衡处理的MMT数据集上,三种机器学习模型都取得了较高的总体分类精度。该数据集中75%的光变曲线来自于三个最大的类。本文作者的实验表明,1D CNN整体上由于前两种方法,实现了90.71%的交叉验证分类准确率,但在较小的类上表象相当差。从结果来看,类别数据量的不平衡性对于SVM、FC方法的影响更大,当使用平衡后的数据集时,二者的经度直接掉到了60%以下,而1D CNN方法则仍然保持有80.07%的综合分类精度。
在MMT平衡数据集上,尽管1D-CNN模型的总体分类准确率偏低,但模型在所有类上实现了类似的性能,如下图所示: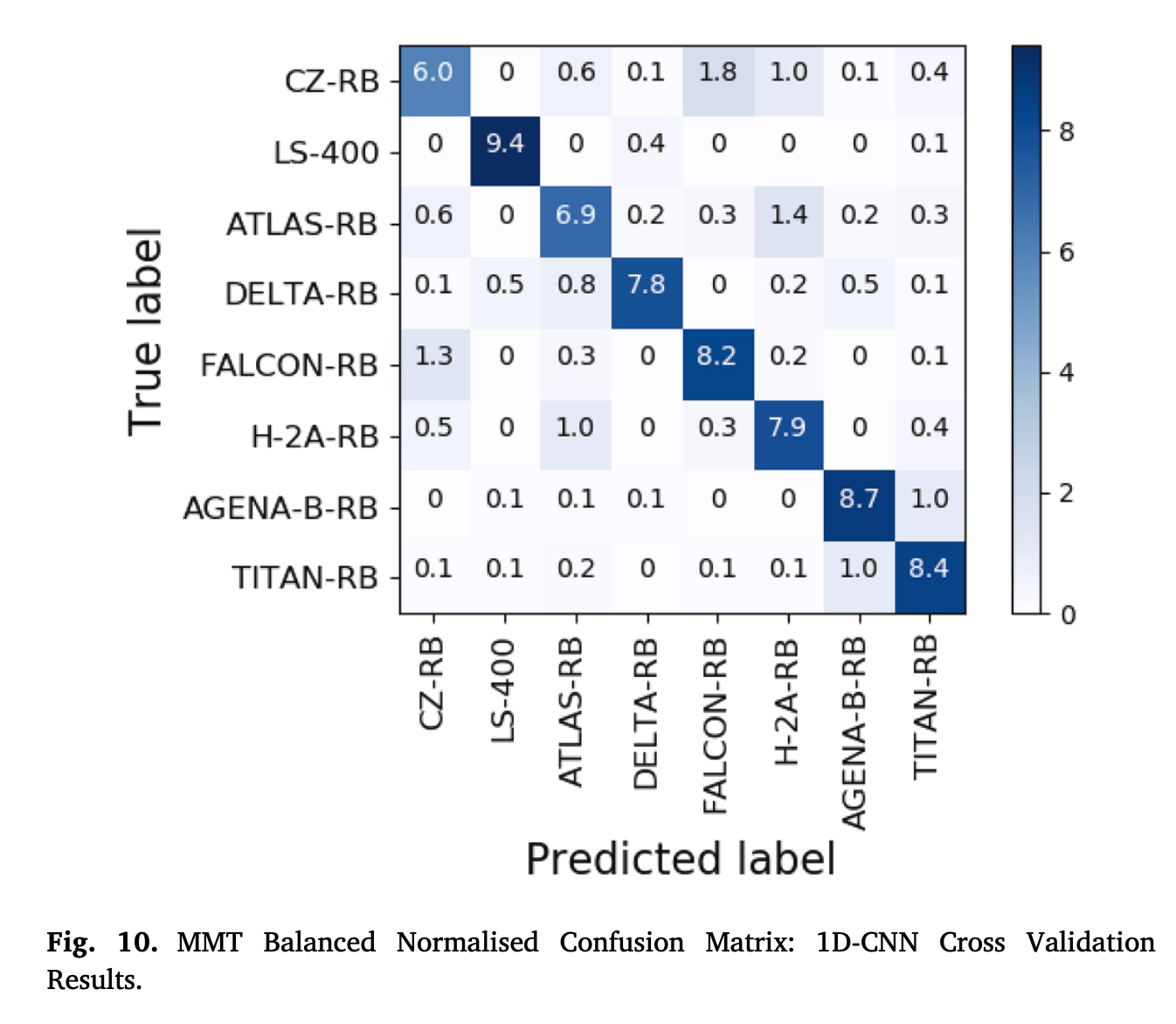
从图中可以看出,相比不平衡数据(文中只有EOS的Confusion Matrix),balanced数据能够使不同类的分类分类精度趋于一致。
下表对MMT平衡数据集的结果进行了更详细的分析,其中显示了F1分数、精度和召回率,以及该数据集中每个类别的unique目标的数量。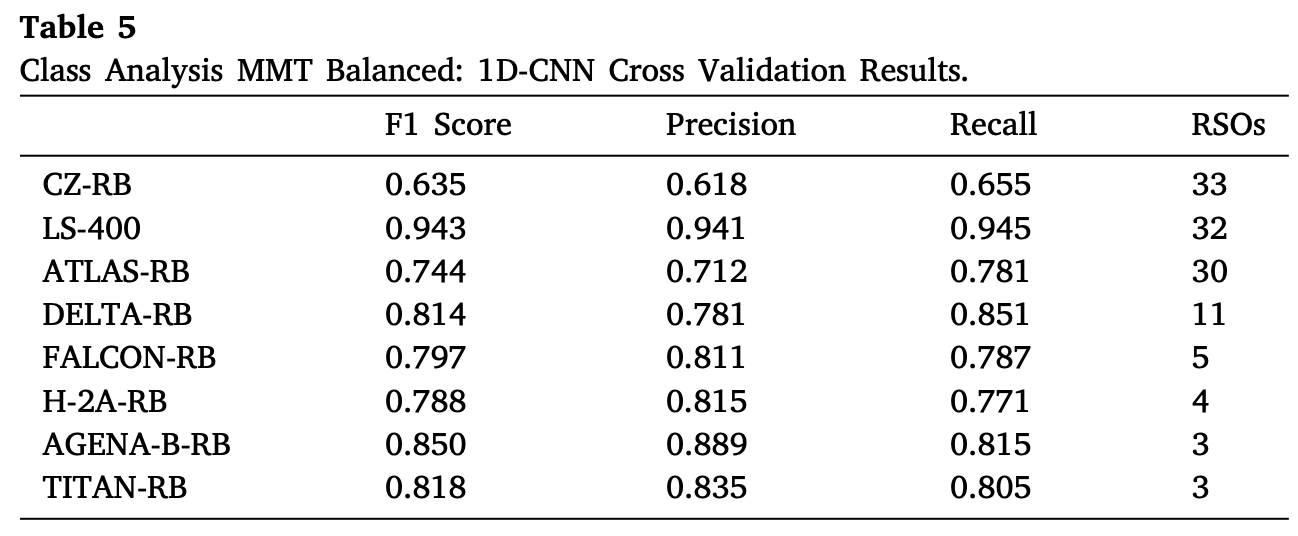
结果表明,该模型在LS-400类别上达到了最佳性能,LS-400是一个箱翼型卫星,其余为火箭体构型。
迁移学习性能分析
下两图表示了迁移学习后的分类精度的变化:![]()
![]()
从图中可以看出,使用Blender预训练,然后将预训练模型迁移至真实数据集上的方法,相比直接使用真实数据集训练的方式,对模型的分类精度有着较高的提升。
结论
(本部分内容较多,直接翻译文章内容)
1D-CNN的多层结构能够学习出不同类型RSO的光变曲线的复杂决策边界,从而在真实数据上实现多目标分类。本文的实验结果支持了这一理论,在每个真实数据集上,1D-CNN的分类精度都明显高于FC神经网络和SVM。在Blender模拟数据集上的对象分类也出现了类似的结果。这表明,与之前研究中使用的FFM数据集相比,本研究中提出的Blender模拟数据集更复杂,仿真数据中类边界之间的划分更少。
根据Blender数据集的归一化混淆矩阵,本文1D CNN模型在区分相似对象方面存在一些困难。大约35%的圆柱体光曲线被错误地归类为SpaceX火箭体,还有相当大比例的SpaceX光曲线被错误地归类为圆柱体。这是意料之中的,因为这些模型都是相同的,除了SpaceX模型的鼻锥和喷嘴。对于所有的旋转轴和方向组合,这些特征对观察者来说都是不可见的,所以在这两个类之间会有许多非常相似的光曲线。同样,不同类型的立方体卫星以及平面的两种不同版本之间也存在一些错误分类。然而,在大多数情况下,模型不会将物体错误地分类为非常不同的形状。这增加了模型能够区分一般形状和特定对象的信心。
在MMT平衡数据集上的结果表明,本文模型一般能够区分不同类型的火箭构型。一个类别所包含的目标数量越少,模型性能越高。这表明本文模型能够学习出单个rso的特定特征,例如旋转周期,并使用这些信息来帮助对物体进行分类。
对于EOS、MMT两个真实数据集来说,类不平衡、训练样本数量的因素,与本文模型性能之间的明显相关性。这两个数据集都偏重于大型碎片,特别是火箭残骸,因为它们更容易被追踪,而且经常旋转。未来EOS的跟踪活动将侧重于从更广泛的对象中收集数据。由于收集真实数据的时间和成本,作者还将探索使用Blender模拟环境为具有有限真实光曲线数据的类模拟特定对象的想法。然后将这些模拟光曲线合并到训练数据中,以尝试改进真实光曲线的结果。由于大多数空间碎片物体可用的信息量有限,该工作的困难在于为Blender中的特定物体开发一个精确的形状及材质模型。
迁移学习是提高模型性能和整体分类精度的有效方法。在两个真实光曲线数据集上,当模型微调部分的训练数据集的大小受到限制时,迁移学习似乎是最有效的。随着训练数据量的增加,迁移学习的好处通常会减少。预计随着特定数据集的训练数据越来越多,这种趋势将持续下去,直到基线1D-CNN模型在没有迁移学习的情况下,与应用了迁移学习的1D-CNN持平或优于后者。然而,如前所述,获取和标记真实的光曲线数据是困难的,特别是对于广泛的类别。这项研究表明,迁移学习可以用来提高小型真实世界光曲线数据集的性能,并减少对长时间密集跟踪活动的需求。
在模拟Blender数据集上的预训练比在任何一个真实数据集上的预训练更有效。这大概是因为Blender的数据集比任何一个真实的数据集都要大得多,并且有更广泛的对象模型,而这两个真实的数据集严重偏向于火箭体类。这也可能是由于两个真实数据集之间的数据特征不同,MMT数据集通常比EOS数据集具有更高的采样率和更短的轨迹。
当目标数据集是MMT平衡数据集时,将有更多的层从预训练的网络中转移过来。传递四层表示卷积层和前两层全连接层都被传递了。这意味着,除了低层的一般特征外,在预训练期间学习到的高层的更具体的特征也被用于目标数据集上的最终网络。此外,在微调过程中,仅将最终输出层设置为可训练层,从而减少了微调时间和计算需求。相比之下,当EOS数据集作为迁移学习的目标数据集时,只有两个卷积层从预训练的网络中转移,并且在微调过程中将大多数层设置为可训练的。与MMT Balanced和Blender模拟数据集相比,这可能是EOS数据集中不平衡类的结果(最后这句话没看懂)。
与之前文献中模拟数据集的结果不同,即使加入迁移学习,在所有4个数据集上的分类结果也没有达到接近100%的准确率。就模拟数据而言,预期这一结果是由于用于生成模拟光曲线的输入参数的可变性增加而产生的。先前基于FFM的模拟对所有光曲线使用相同的初始历元、初始四元数和角速率,从而降低了分类任务的复杂性。在现实世界中,预计一定比例的光曲线将不能提供足够的信息来确定分类。这是由于方向轴与物体的复杂性之间的关系,以及1D光曲线数据中可观测信息的局限性。此外,为了使所提出的方法有效,实际光曲线必须足够精确,以使物体旋转引起的星等变化与噪声引起的变化区别开来。
综上所述,本文的提出的1D CNN及迁移学习的方法,被证明为是一个有效处理真实数据量不足与深度神经网络应用之间矛盾的方法。
[^1]: Allworth J, Windrim L, Bennett J, et al. A transfer learning approach to space debris classification using observational light curve data[J]. Acta Astronautica, 2021, 181: 301-315.