Online Shape Modeling of Resident Space Objects Through Implicit Scene Understanding
本文为康奈尔大学Sibley School of Mechanical and Aerospace Engineering的Aneesh M. Heintz等人于2022年在Journal of Aerospace Information System上发表的文章,采用了一种view-synthesis网络来隐式表达小天体的形状,用于在小天体探测任务的抵近阶段(Approach)和初步探测阶段(Preliminary Survey)的resolved图像中来生成目标的形状。
本文主要提出了:
- 一个包含两个深度网络的框架,包含一个view-synthesis network和一个graph convolutional network;
- view-synthesis为系统提供环境理解能力,使用现有图像训练好该网络后,可以用来生成新的观测图像;
- graph convolutional network则使用多视图图像集合来构建物体的三维图表示,从而生成物体的形状模型
本文作者认为,经过仿真实验测试,本文提出的pipeline在模型精确性方面,有着与state-of-art methods相当的竞争力。此外,本文的pipeline能够在多环境任务中应用。最后,相比state-of-art methods,本文方法有着较高的计算效率。
数据
本文的训练和测试均采用仿真数据。本文首先设定一系列轨道,这些轨道分为两类:抵进轨道和Preliminary survey轨道(文中提到每一类轨道设定500条,这或许是为了验证本文Pipeline在不同环境下的性能?)。对于Preliminary survey来说,使用的轨道为简单球形轨道,每条轨道上选择40个采样点。对于抵近轨道,使用Keplerian椭球轨道,目标将位于轨道的交点,每条轨道选择100个采样点。在采样点,将采集对目标的成像和当前飞行器的位置和姿态,构成image-pose pair。这些采样点都要在距离目标100km以内,防止距离太远目标变成点目标。仿真中,观测的目标使用四个已知形状的天体:Bennu、Itokawa、Toutatis、Mithra,其中Mithra只有地基雷达的低分形状模型,因此在评估建模精度时,只使用前三个。
对每条轨道的观测中,随机选择m组image-pose对,用来构成”场景”(constitute a scene),随机选择一副图像作为query pair(这里的qurey pair是view-synthesis网络中所需要的),如图一所示;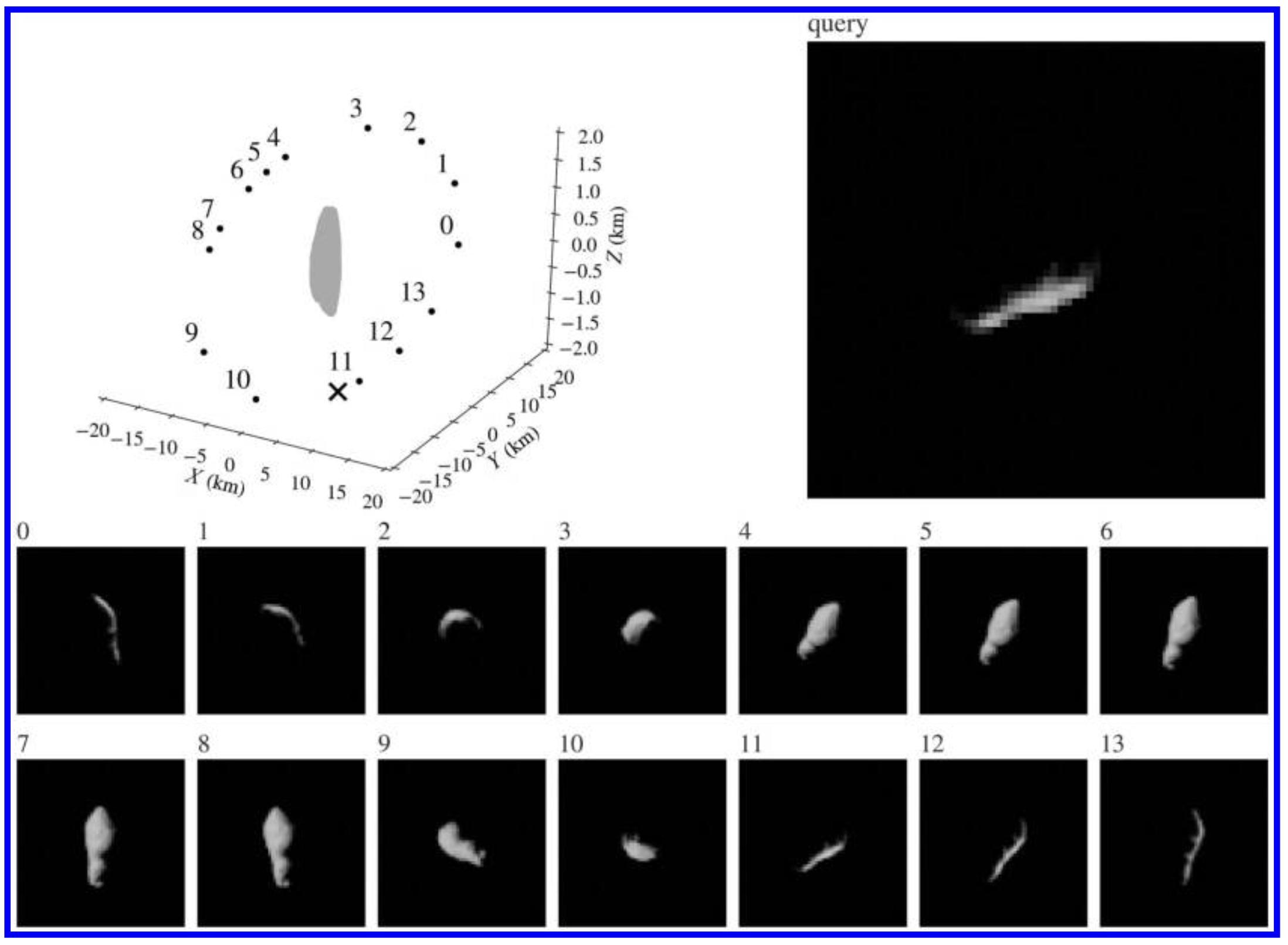
这些图像的分辨率都是$64\times 64$,所有图像都通过Blender生成。
光照条件将采用随机的方式,以保证训练集能够覆盖不同的光照条件(这里的随机或许是一条oribit一个光照方向?)。网络随机选取40000个场景,即40000个image-pose pair来进行训练。飞行器和目标之间的距离虽然要在100km以内,但也不能太近,从而模仿探测任务的早期阶段。对位姿来说,由于位姿是网络的输入,因此需要通过其他方法来得到位姿,为了方便,本文将采用SfM来得到位姿,但也可以通过其他方法来实现(本文作者的另一篇文章中,提出了使用NeRF来进行位姿估计的方法)。
Pipeline Architecture
本文pipeline的结构如下图所示: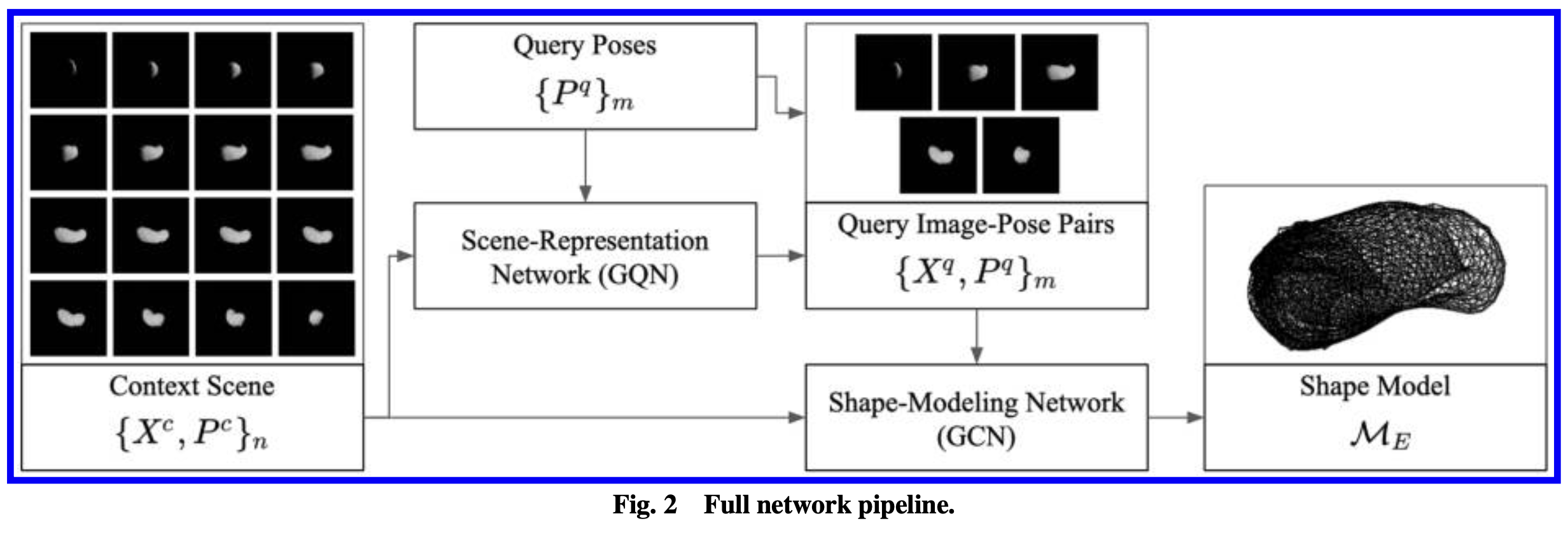
Pipeline分为两个部分,首先是Scene-Representation部分,使用文献[^1]中提到的GQN网络(Generative Query Netword)。关于该网络的细节,需要去相应文献中阅读。该网络的作用是理解场景信息,其结果是从输入的Sence中,学习出场景的信息,并得到新的视角下的图像。换句话说,GQN网络的作用和NeRF是相同的,但这种VAE-based网络有着相对更小的网络模型,运算速度会快一些。经过取舍,本文最终选择了GQN来作为场景理解的主干网络。
GQN的输入是一个场景序列${X^c, P^c}$,称为Context,Qurey序列只输入一系列的位姿${P^q}_m$,最终将输出更多的image-pose pair(文中的图与公式有些对不上)。这些结果如下所示: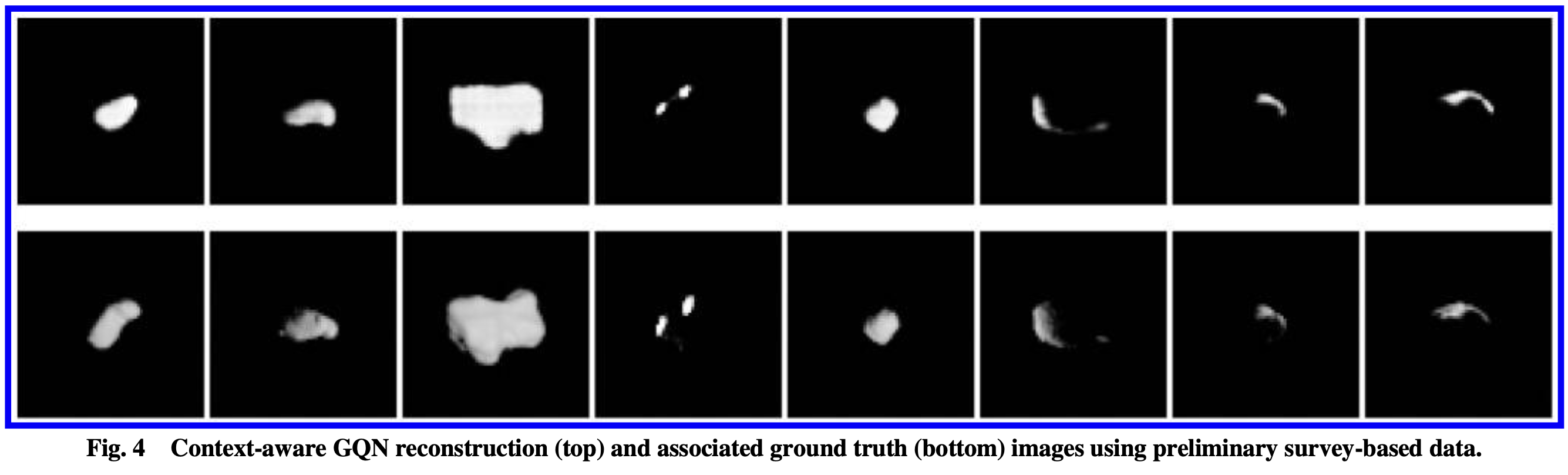
原始的Context和GQN生成的Context,将作为Shape-Modeling Graph-convolution Network(GCN)的输入。该部分采用pixel2mesh网络[^2]的主干结构,但进行了多视角处理。同样,该网络的细节参考相应文献。
实验与结论
本文进行了:1)对两个网络单独进行了测试;2)对整个pipeline进行了测试。
单独测试
GQN结果
不太重要。
GCN结果
实验结果表明,Preliminary survey轨道相比approach轨道,有着更好的表现,但并未给出具体的F1 score和模型的RMS对比。两段观测结果都表明,在不将GQN网络所生成的,在新视角下的图像加入GCN输入时,随着初始Context中包含的scene的增加,F Score将提升,特别是增加到25组scene时。
结果如下图所示: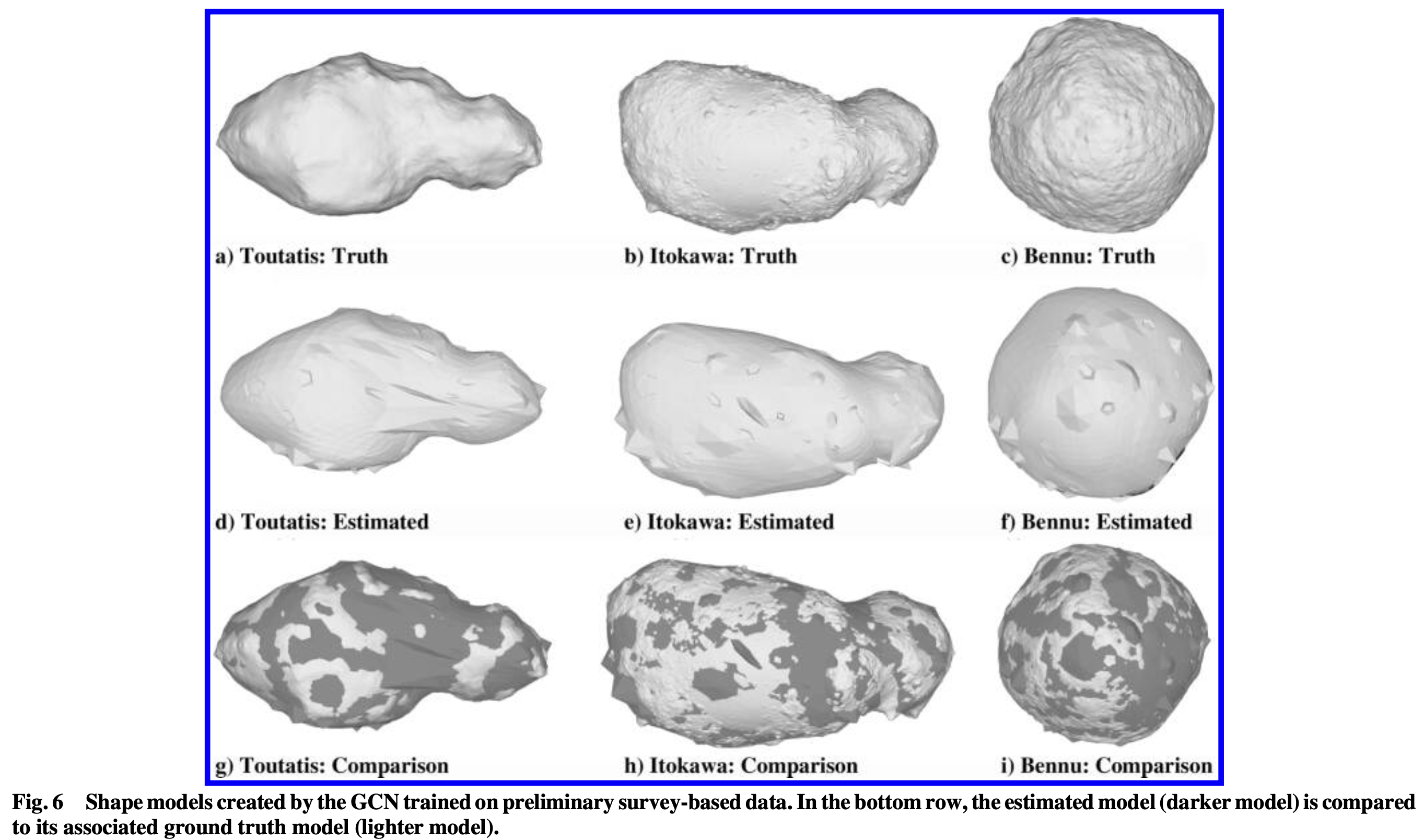
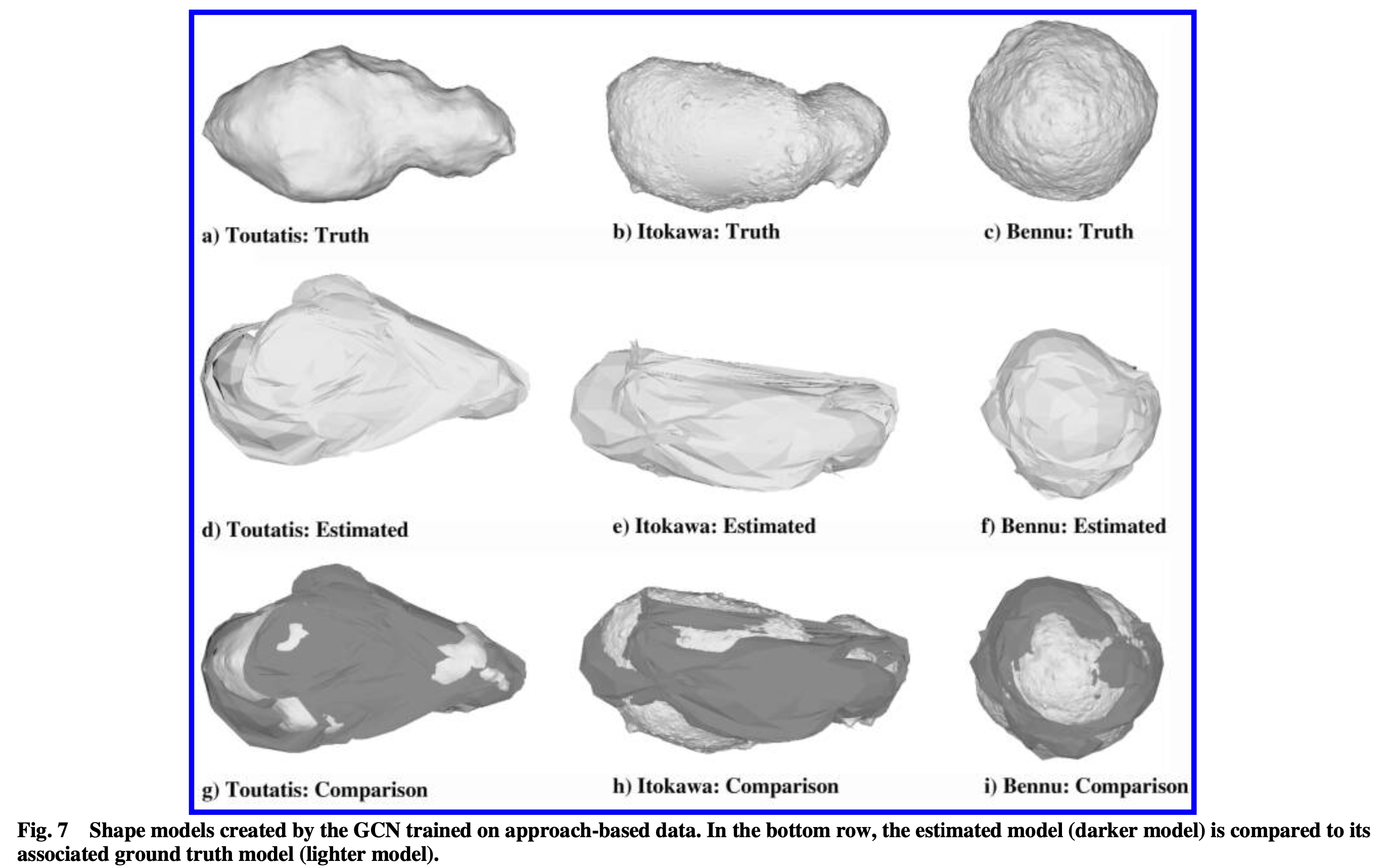
Pipeline测试
对整个pipeline的测试有着相似的结果,Preliminary Survey轨道的三维建模精度高于Approach轨道,context中的scene越多,结果也越好。除此之外,本文还与现有的方法进行了对比,如下表所示: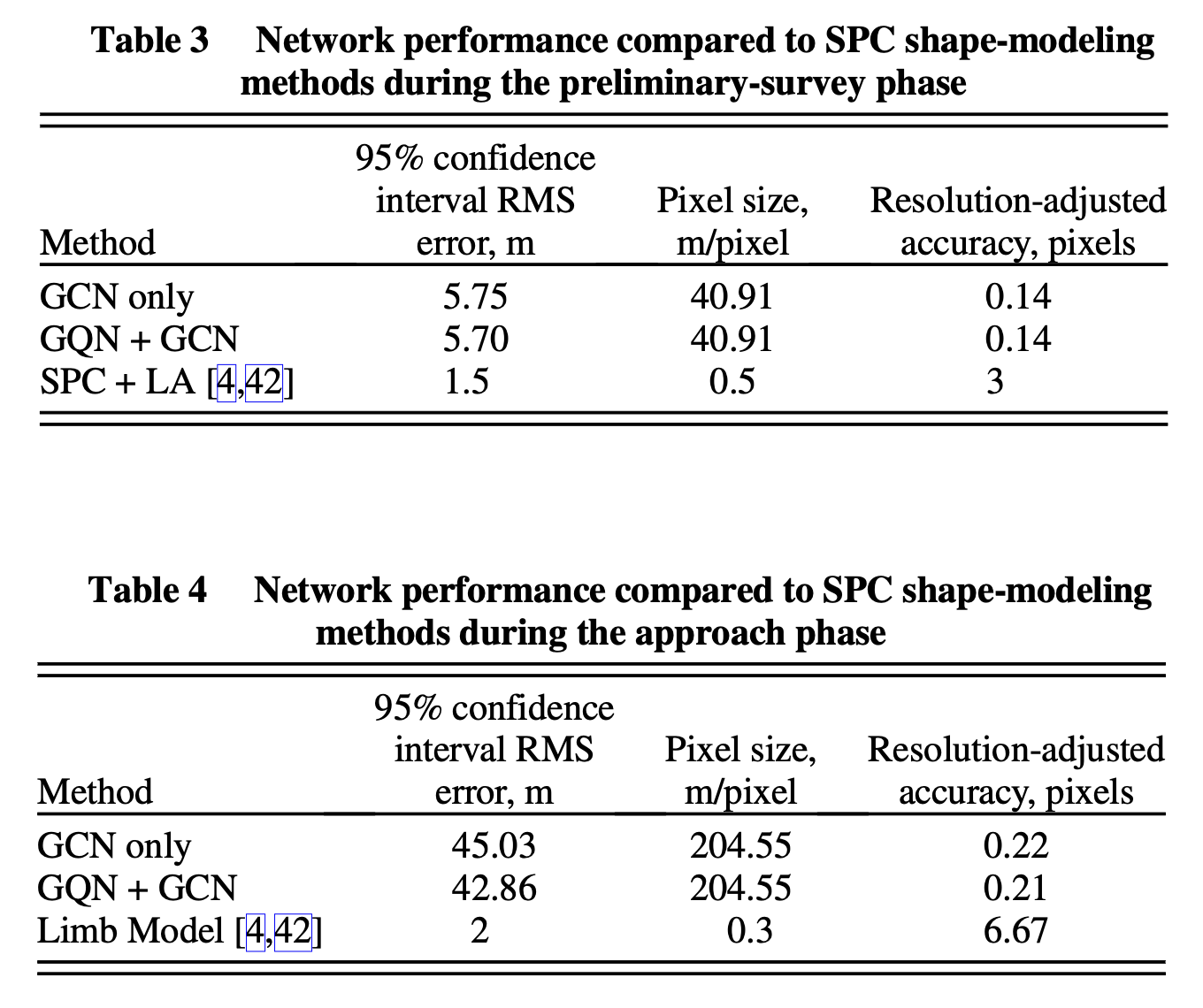
从结果上看,在Preliminary段,本文的pipeline所构建的模型,相比SPC+LA的方法,在像素分辨率上毫无优势(40.91m v.s. 0.5m),但修正精度要高于SPC+LA(可以理解为像素误差)。在Approach段,有着同样的结论。
[^1]: Nguyen-Ha, P., Huynh, L., Rahtu, E., and Heikkilä, J., “Predicting Novel Views Using Generative Adversarial Query Network,” Scandi- navian Conference on Image Analysis, Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Vol. 11482 LNCS, Springer, 2019, pp. 16–27.
[^2]: Wang, N., Zhang, Y., Li, Z., Fu, Y., Yu, H., Liu, W., Xue, X., and Jiang, Y. G., “Pixel2Mesh: 3D Mesh Model Generation via Image Guided Deformation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 43, No. 10, Oct. 2021,
pp. 3600–3613.